О проекте
Мой самый первый проект, который я делал в коллаборации со своим другом Артёмом. Суть бота такова, что он автоматически скачивает видео с YouTube, парсит его описание и метаданные и в красивом виде отправляет в указанный Telegram-канал. Да, я знаю, что таким способом мы можем очень сильно нарушать авторские права)))) Но этот канал был приватным, только для личного пользования
История возникновения такой идеи
Мы с Артёмом очень любим слушать музыку, особенно техно. В 2021 году для меня самым используемым источником новых треков стал YouTube-канал HATE. Там каждый день выкладывают треки целыми альбомами, было всегда что послушать каждый день. Я захотел автоматизировать пополнение своего плейлиста с помощью Telegram, чтобы на личном канале была всегда актуальная библиотека новой, свежей музыки.
Чему научился
С этим проектом у меня в целом начинается мой путь в IT. Здесь я впервые окунулся в backend-разработку: узнал, что такое Flask, как работают вебхуки, как работают телеграм-боты, как организовать проверку на дубликаты видео с помощью кэш-памяти в виде sqlite базы данных и многое другое интересное.
У Артёма есть Raspberry Pi 3, на котором мы развернули бота. Это был первый раз, когда я работал с сервером по SSH - поднимал и настраивал окружение, следил за нагрузками и т.д. Я помню, как мы сильно накосячили с Python-окружениями и очень испортили структуру pip-пакетов, что аж пришлось заново перепрошивать Pi. А ещё мы настроили туннелирование через белый IP Артёма, чтобы я мог напрямую подключаться к нашей машине.
И я вам скажу, что эта маленькая плата вполне успешно справлялась с ботом! Да, было узкое место в виде очень ограниченной мощности для параллельной обработки нескольких видео с помощью ffmpeg, но с задачей он справлялся успешно, учитывая, что в день было около 40 новых треков.
Как работал бот
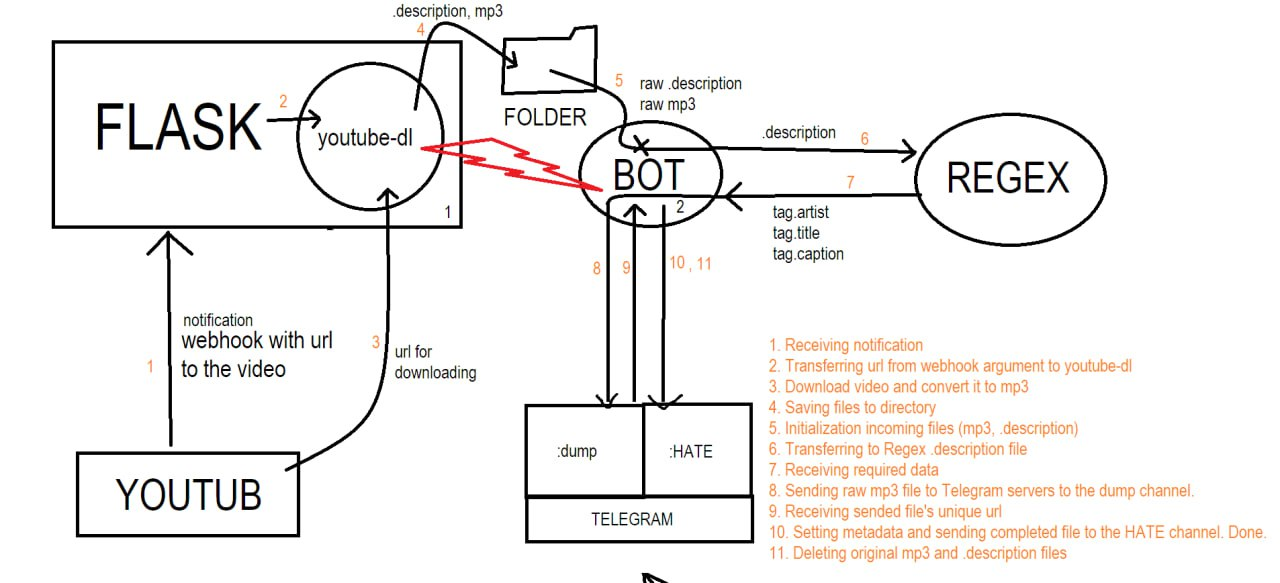
Архитектура выглядела примерно так:
- YouTube PubSubHubbub отправлял webhook при публикации нового видео
- Flask-сервер принимал событие
- Видео добавлялось в очередь SQLite
- Воркер скачивал видео и метаданные
- ffmpeg обрабатывал медиа
- Telegram-бот публиковал готовый пост в канал
Сложности
После той истории с перепрошивкой Pi 3 я понял, что такое виртуальные окружения в Python и зачем они вообще нужны. До этого я просто прописывал pip install, не подозревая, что так делать вообще-то нельзя, пока не напутал все пакеты на сервере. После того случая я всегда использовал venv в последующих проектах, а спустя какое-то время я узнал про uv и разработка стала ещё удобнее.
Я очень долго не мог понять, что такое вебхуки и как работать с хабом событий. Нужно было всего лишь один раз прочитать их спецификацию и выполнить все требования хаба, чтобы правильно возвращать ответы серверам Google.
В этой системе вебхуков была проблема, что 1) мог прийти повторный ивент с видео, который уже был выложен на нашем канале; 2) в одну секунду прийти 10 новых ивентов. Мы с Артёмом решили проблему методом очередей, реализованном на sqlite3: все видео, которые ещё не были обработаны, были временно записаны в таблицу, пока воркер-обработчик видео не заберёт их и не удалит из таблицы. Воркер работал до тех пор, пока таблица не становилась пустой.
На выходе получилась крутая автоматизация, которая всегда снабжала нас свежими релизами от техно-артистов
Как бы я сделал сейчас
Я бы вынес обработку видео в отдельный воркер-сервис и масштабировал его горизонтально - несколько инстансов параллельно обрабатывают единую очередь. Вместо SQLite в роли очереди сообщений использовал бы RabbitMQ по такой схеме: PubSubHubbub пушит ивент - Flask-сервер кладёт сообщение в очередь - воркеры разбирают задачи независимо друг от друга и каждый пушит в телеграм-канал самостоятельно.